本文是澳门大学陈俊龙教授及其团队“Broad Learning System: An Effective and Efficient Incremental Learning System Without the Need for Deep Architecture”的中文综述,原文将在IEEE Transactions on Neural Networks and Learning Systems, Vol. 29, Issue 1, 2018 发表。
论文链接:
http://ieeexplore.ieee.org/document/7987745
文章代码下载地址:
http://www.broadlearning.ai
正文
深层结构神经网络和学习已经在许多领域得到应用,并在大规模数据处理上取得了突破性的成功。目前,最受欢迎的深度网络是深度信任网络(Deep Belief Networks,DBN),深度玻尔兹曼机器(Deep Boltzmann Machines,DBM)和卷积神经网络(Convolutional neural Networks,CNN)等。虽然深度结构网络非常强大,但大多数网络都被极度耗时的训练过程所困扰。其中最主要的原因是,上述深度网络都结构复杂并且涉及到大量的超参数。另外,这种复杂性使得在理论上分析深层结构变得极其困难。另一方面,为了在应用中获得更高的精度,深度模型不得不持续地增加网络层数或者调整参数个数。因此近年来,一系列以提高训练速度为目的的深度网络以及相应的结合方法逐渐引起人们关注。其中,宽度学习系统提供了一种深度学习网络的替代方法,同时,如果网络需要扩展,模型可以通过增量学习高效重建。
单层前馈神经网络(Single layer feedforward neural networks,SLFN)已被广泛应用于分类和回归等问题,因为它们可以全局地逼近给定的目标函数。一般来说,基于梯度下降的SLFN的泛化性能对某些参数设置,例如学习率,非常敏感。更重要的是,他们通常在训练时收敛到局部最小值。为此,由Yoh-Han Pao教授在1990年代提出的随机向量函数链接神经网络(random vector functional link neural network,RVFLNN)提供了不同的学习方法。
RVFLNN有效地消除了训练过程过长的缺点,同时也保证了函数逼近的泛化能力。因此,RVFLNN已经被用来解决不同领域的问题,包括函数建模和控制等。虽然RVFLNN显著提高了感知器的性能,但是在处理以大容量和时间多变性为本质特性的大数据时,这种网络并不能胜任。为了对中等大小数据进行建模,C. L. Philip Chen (陈俊龙) 在1990年代末也提出了一种动态逐步更新算法(增量学习),用于更新RVFLNN中新增加输入数据和新添加的增强节点的输出权重。这项工作为调整遇到新的输入数据的系统铺平了道路。
另一方面,近年来除了数据量的增长之外,数据的维度也大大增加。假如将原始的“大”数据直接输入神经网络,系统往往无法再保持其有效性。如何处理高维数据最近成为迫在眉睫的问题。克服这个难题的两个常见做法是降维和特征提取。其中,特征提取目的是寻求从输入数据到特征向量的最佳函数变换。易于实现和效率突出的特征提取常用方法包括,变量排序(variable ranking ),特征子集选择(feature subset selection ),惩罚最小二乘法(penalized least squares),随机特征提取方法,包括非自适应随机投影(non-adaptive random projections)和随机森林(random forest)以及基于卷积的输入映射等等。
因此,对于特征提取,可以采用“映射特征”作为RVFLNN的输入。本发明中提出的宽度学习系统(Broad Learning System,BLS)是基于将映射特征作为RVFLNN输入的思想设计的。此外,BLS可以在新加入的数据以有效和高效的方式更新系统(输入的增量学习)。BLS的设计思路为:首先,利用输入数据映射的特征作为网络的“特征节点”。其次,映射的特征被增强为随机生成权重的“增强节点”。最后,所有映射的特征和增强节点直接连接到输出端,对应的输出系数可以通过快递的Pseudo伪逆得出。为了在宽度上扩展特征节点和增强节点,论文中额外设计了对应的宽度学习算法。同时,如果网络结构需要扩展,论文同时提出了无需完整网络再训练的快速增量学习算法。
论文的其余结构如下。首先介绍RVFLNN,如图1-3所示。其次,给出了所提出的宽度学习算法的细节。第三,在MNIST分类和NORB分类中实验宽度学习系统,同时与其他各种深度神经网络进行比较。最后,给出关于宽度学习系统的结论和讨论。
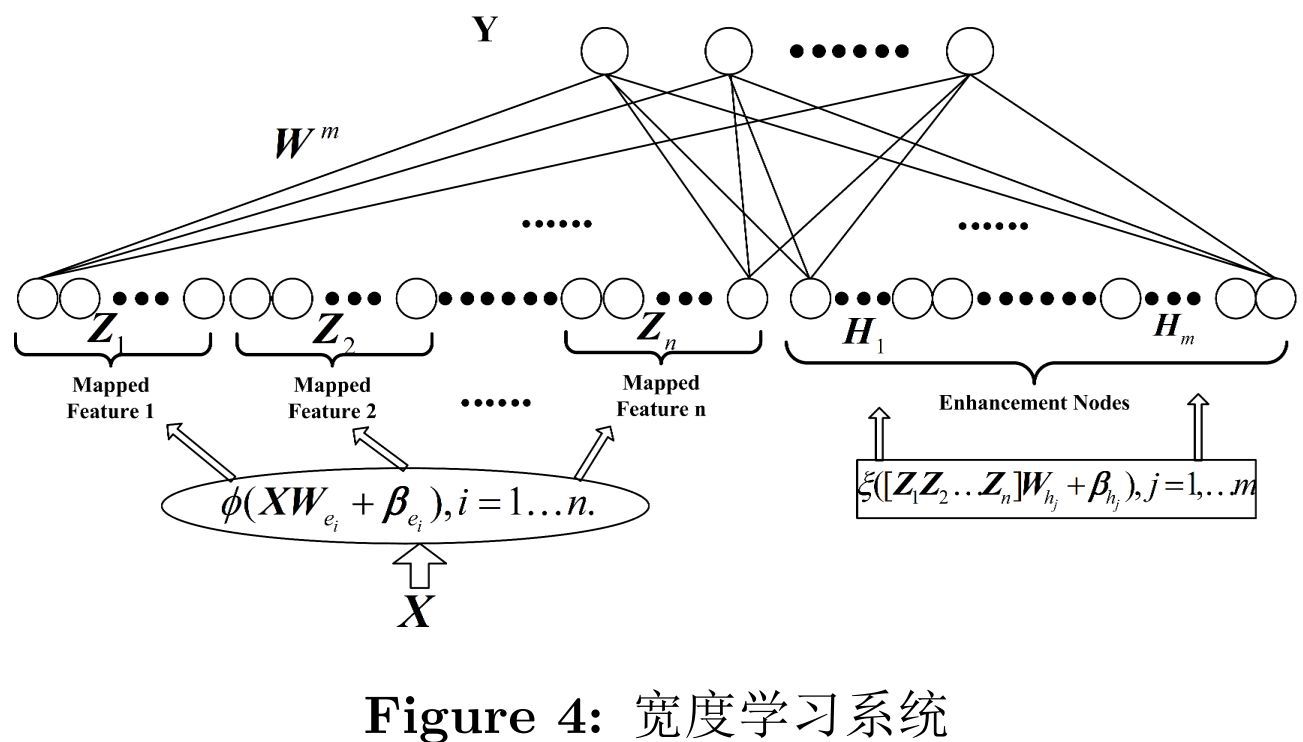
如图4所示,假设我们提供输入数据X并利用函数ϕi(XWei+βei)映射产生第i组映射特征Zi。其中,Wei是具有适当维度的随机权重系数。给定记号Zi≡[Z1, . . . , Zi]表示前i组所有映射特征。同样的,第j组增强节点ξj(ZiWhj+βhj )被记为Hj,同时前j组所有增强节点被记为Hj≡ [H1,. . . , Hj]。实际上,根据建模任务的复杂性,可以选择不同的i和j。此外,当i≠k 时,ϕi 和ϕk 可以是不同函数。同样,当j≠r,ξj 与ξr也可以不同。在不失一般性的情况下,本文省略了随机映射ϕi和ξj 的下标。图4表征了论文提出的宽度学习网络的结构。
论文中还提供了三种不同的增量学习算法,包括增强节点增量,特征节点增量和输入数据增量(图5)。由于更新输出层的伪逆时,只需要计算新加入的节点的伪逆,增量学习的训练过程节省了大量的时间。从这个角度分析,宽度学习系统可以高效重建需要在线学习的模型。
在BLS的基础上,我们提出了一种新的神经-模糊模型,我们称之为模糊BLS。该模糊BLS保持了BLS的基本结构,将BLS的特征节点部分替换为Takagi-Sugeno型模糊子系统,同时去掉了原来的稀疏自联想(如图6-7所示)。输入数据会送入每一个模糊子系统进行处理,然后将每个模糊子系统的输出作为增强节点的输入。在模糊BLS中,我们也只需要通过伪逆来计算顶层权重,而模糊子系统部分的参数将通过聚类和随机产生的数据来决定。这样我们可以减少模糊规则数,大大加快模糊子系统部分计算速度。在函数逼近和分类问题上,与经典的和目前主流的神经-模糊模型相比,模糊BLS在精度和训练时间上都表现出极大的优势。关于模糊BLS的论文目前正在审稿中,之后我们会提供更详细的描述。
如果在特征节点内,增强节点内,以及特征节点和增强节点之间建立不同的权重连接,宽度学习网络可以产生不同的变体。其中一种典型的结构如图8,图9所示。对应的数学模型以及增量学习模型可以在即将发表的论文中查看。
另一种变形的把宽度学习结构里的串联增强节点,这样就可以成为宽深学习网络,如图10,图11所示。宽深网络数学模型以及增量学习模型也可以在即将发表的论文中查看。
最后,相关实验结果被给出以验证所提出的宽度学习系统。为了确定提出的系统的有效性,论文测试了宽度学习系统在MNIST数据下的分类表现。同时,为了证明BLS的有效性,我们将与现有“主流”方法的分类能力进行比较,包括堆叠自动编码器(Stacked Auto Encoders,SAE),另一个版本的堆叠自动编码器(another version of stacked autoencoder,SDA),深度信念网络(Deep Belief Networks,DBN),基于多层感知器的方法(Multilayer Perceptron based methods,MLP)深玻尔兹曼机(Deep Boltzmann Machines,DBM),两种的基于ELM的多层结构,分别表示为MLELM和HELM。在我们的实验中,网络由10×10特征节点和1×11000增强节点构成。相关的权重均为随机生成。BLS的测试精度以及其他所提到的深度算法测试精度如表格1所示。虽然98.74%不是最优秀的(事实上,深度学习的表现仍然比SAE 和MLP好),BLS在服务器上的训练时间被压缩到了29.6968秒。此外,应该注意的是,MNIST数据特征的数量减少到100。这个结果符合学者在大数据学习中的直觉,也就是现实应用中的数据信息通常是冗余的。表格2是BLS在NORB数据库上的分类表现以及和其他模型的比较,最后两行BL是“宽度学”的结果,其它都是深度学习算法的结果,表明宽度学习算法是又快又准。
另外,我们还对增加的输入测试增量宽度学习算法。测试结果如表格3所示,表明设计的算法高效并且有效。从而,我们进一步得出结论,本文所提出的宽度学习算法,可以逐步更新建模系统,而无需从一开始重新训练整个系统。尤其当系统收集到新输入数据时,现有网络结构迫切需要更新以反映系统的真实性和完整性。这一功能完全适用于大数据时代。基于上述实验,宽度学习系统在训练速度方面明显优于现有的深度结构神经网络。此外,与其他MLP训练方法相比,宽度学习系统在分类准确性和学习速度都有长足的表现。与数百个迭代的高性能电脑下几十小时或几天的训练相比,宽度学习系统可以在几十秒或几分钟内轻松构建,即使在普通PC中也是如此。
我们对20万的数据,每个数据维度从一万维度到三万维度,做测试,在3分钟到50分钟之内,宽度学习都很快的找到神经网络的权重。另外在函数逼近和回归问题上,BLS和模糊BLS都表现出较高的精度,具体参数设置和结果见表格4和5。
综上所述,我们认为BLS以及它的各种变体和扩展结构具有良好的发展潜力,在实际应用中表现出其快速且高精度的优秀性能。